ساخت سنسور عواطف صوتی با استفاده از یادگیری عمیق


انسانها به صورت پیچیده و به طرق مختلف احساسات و عواطف خود را ابراز میکنند. برای مثال، فردی که در حال صحبت است، علاوه بر کلمات از آهنگ صوت، زیر و بمی صدا، حالات چهره و زبان بدن نیز برای انتقال پیام استفاده میکند. به همین دلیل است که جلسات کاری حضوری را به ویدئوکنفرانس و ویدئوکنفرانسها را به ایمیل و پیام نوشتاری ترجیح میدهیم. هرچه نزدیکی بیشتر باشد، گسترهی ارتباط نیز افزایش خواهد یافت.
نرمافزارهای تشخیص صدا در سالهای اخیر پیشرفت زیادی داشتهاند. این فناوری میتواند به خوبی اصوات را تشخیص داده و آنها را برای تولید کلمات و جملات کنار هم قرار دهد. اما صرفاً تبدیل گفتار به نوشتار نمیتواند پیام گوینده را منتقل کند. حتی صرف نظر از حالات چهره و زبان بدن نیز نوشتار در مقایسه با صدا محدودیت زیادی در دریافت حالت عاطفی افراد دارد.
در ابتدا تصمیم گرفتیم یک سنسور عواطف صوتی بسازیم، چون پروژهی جالب و مهیجی به نظر میرسید. با بررسی دقیقتر مسئله متوجه شدیم تشخیص عواطف از روی صدا میتواند کاربردهای جالبی داشته باشد؛ تصور کنید تلفن همراه هوشمند شما میتوانست متناسب با عواطف شما آهنگی انتخاب کند، مثلاً وقتی ناراحت هستید موسیقی پرانرژی پخش کند؛ یا واحدهای خدمات مشتری میتوانستند برای آموزش کارکنان یا اندازهگیری میزان رضایت و خشنودی مشتریان از تماس، از فناوری تشخیص عواطف استفاده کنند.
دانلود و مشاهده عناوین ماهنامه ” اقتصاد دیجیتال” شماره ۱۳، مهرماه ۱۴۰۰
دادهها
برای ساخت طبقهبندی عواطف از دیتاستهای RAVDESS، TESS و SAVEE استفاده کردم که همگی به صورت آزاد در دسترس عموم قرار دارند (برای استفاده از SAVEE یک ثبتنام ساده لازم است). در این دیتاستها فایلهای صوتی در هفت دسته قرار دارند: خنثی، خوشحال، ناراحت، عصبانی، ترسیده، منزجر و متعجب. با استفاده از این داده ها در کل به بیش از ۱۶۰ دقیقه صوت (۴۵۰۰ فایل صوتی برچسبخورده) دسترسی خواهید داشت که توسط ۳۰ مرد و زن تولید شدهاند؛ در این فایلها، افراد یک عبارت کوتاه و ساده را با یک حالت عاطفی خاص بیان میکنند.

استخراج ویژگی
در مرحلهی بعد باید ویژگیهای مفیدی را تشخیص میدادیم که بتوان آنها را از فایل صوتی استخراج کرد. در ابتدا قصد داشتیم از تبدیلات فوریه زمانکوتاهبرای استخراج اطلاعات مربوط به فرکانس استفاده کنیم. با این حال برخی از تحقیقاتی که در این حوزه انجام شده نشان میدهند کاربرد تبدیلات فوریه در برنامههای تشخیص صدا مشکلات و نواقص زیادی دارد؛ زیرا با اینکه بازنمایی فیزیکی بسیار خوبی از صدا به دست میآورد، قادر به درک حالت فرد نیست.
راه بهتر برای استخراج ویژگی از فایل صوتی استفاده از ضریب کپسترال فرکانس مل یا MFCC است. هدف ضرایب MFCC بازنمایی فایل صوتی به نحوی است که همخوانی بهتری با احساس فرد داشته باشد.
جهت مشاهده ودانلود ماهنامه ” اقتصاد دیجیتال” اینجا کلیک نمایید.
برای تولید MFCC از صوت باید بدانیم میخواهیم از چند مقدار فرکانس استفاده کنیم و پهنای گام زمانی که برای قطعهبندی استفاده میکنیم چقدر است؛ این موارد سطلبندی دادههای خروجی MFCC را تعیین میکنند. در برنامههای تشخیص صدا متداول است ۲۶ سطل فرکانسی ۲۰ هرتز تا ۲۰ کیلوهرتز اجرا کرده و تنها از ۱۳ مورد اول برای ردهبندی متداول استفاده کنیم. بیشتر اطلاعات مفید در بازههای فرکانسی پایین قرار دارند و استفاده از بازهی فرکانسی بالاتر میتواند منجر به عملکرد ضعیف شود. اندازهی گام زمانی نیز معمولاً مقادیر بین ۱۰ تا ۱۰۰ میلی ثانیه دارند؛ ما در این پروژه تصمیم گرفتیم از گام ۲۵ میلیثانیه استفاده کنیم.
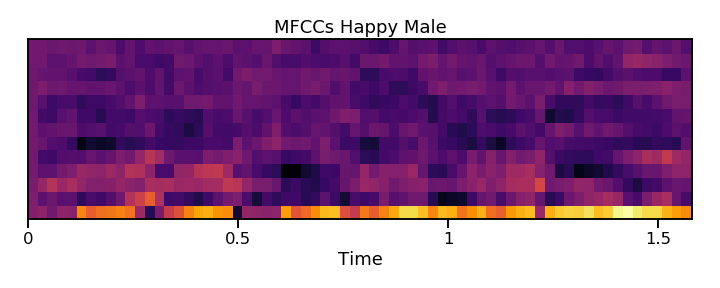
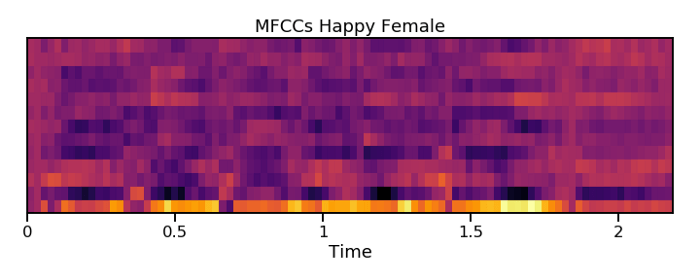
بعد از تولید ضرایب MFCC میتوانیم برای مصورسازی صوت، آنها را روی یک نقشهی حرارتی رسم کنیم. با انجام این کار نمیتوان تفاوتهای آشکار بین دستههای عاطفی مختلف را مشخص کرد؛ نه به دلیل کمبود الگوها، بلکه بدین خاطر که افراد در مورد شناسایی تفاوتهای عاطفی نهان به صورت دیداری آموزش ندیدهاند. با این وجود، این نقشههای حرارتی میتوانند به راحتی تفاوت بین گویندههای زن و مرد را مشخص کنند.
آموزش یک شبکهی عصبی پیچشی
وقتی ضرایب MFCC را تولید میکنیم، مسائل دستهبندی صوت در اصل به مسائل بازشناسی تصویر تبدیل میشوند. در نتیجه ابزار، الگوریتمها و تکنیکهایی که در حوزهی بازشناسی تصویر کاربرد دارند، در مسئلهی ما یعنی دستهبندی صدا نیز کارآمد خواهند بود. برای حل مسئلهی دستهبندی عواطف تصمیم گرفتیم از یک CNN (شبکهی عصبی پیچشی) استفاده کنیم زیرا این شبکهها در بازشناسی صوت و همچنین تصویر عملکرد خوبی داشتهاند.
قبل از آموزش CNN، دادههای دیتاست را با نسبت ۸۰/۲۰ و به صورت تصادفی به فایلهای آموزشی و آزمایشی تقسیم کردم. سپس چند گام پیشپردازشی روی فایلهای آموزشی اجرا کردم. این فرآیند برای هر فایل بدین صورت پیش رفت:
- حذف سکوت
- انتخاب چندین پنجرهی ۰.۴ ثانیهای به صورت تصادفی
- تعیین MFCC برای هرکدام از پنجرهها و تولید یک آرایهی ۱۳×۱۶
- ضریب MFCC را بین ۰ تا ۱ مقیاسبندی میکنیم (این گام بسیار مهم است، زیرا از برازش مدل در تناسب با درجهصدای صوتهای ضبط شده جلوگیری میکند)
- برچسبهای عاطفی فایلهای اصلی را به هرکدام از پنجرهها اختصاص میدهیم.
بعد از تکمیل گام پیشپردازش، به ۷۵۰۰۰ پنجرهی ۰.۴ ثانیهای برچسبخورده برای آموزش دست یافتم؛ هر پنجره توسط یک آرایهی ۱۳×۱۶ بازنمایی میشود. سپس CNN را با استفاده از این دادهها ۲۵ دور آموزش دادیم.
آزمایش مدل
فرآیندی مشابه با آنچه بالاتر توضیح داده شد را بر روی مجموعهی آزمایشی نیز اجرا کردیم. سپس از این مجموعه برای محک مدل استفاده کردیم. فرآیند انجام شده برای هر فایل در مجموعهی آزمایشی بدین شکل بود:
- حذف سکوت
- تهیهی پنجرههای لغزان ۰.۴ ثانیهای با گامهای زمانی ۰.۱ ثانیهای (برای نمونه، اولین پنجره از ۰.۰ ثانیه تا ۰.۴ ثانیه و دومین پنجره از ۰.۱ تا ۰.۵ ثانیه)
- تعیین ضریب MFCC، در مقیاس ۰ تا ۱، برای هرکدام از پنجرهها
- دستهبندی هر پنجره و تولید خروجی تابع softmax
- جمع پیشبینیهای مربوط به هر پنجره
- پیشبینی نهایی، دستهای است که بعد از جمع مقدار بیشینه را دارد.
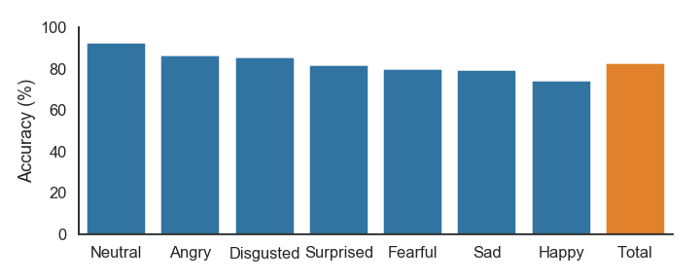
با اجرای این فرآیند روی ۸۹۹ فایل موجود در مجموعهی آزمایشی، به میزان دقت ۸۳% دست یافتیم؛ مقداری که رسیدن به آن حتی برای یک انسان هم دشوار به نظر میرسد. دقت مربوط به شناسایی هر عاطفه در نمودار پایین نشان داده شده است:
برداشت نهایی
شاید با خواندن این نوشتار فکر کنید ساخت، آموزش و آزمایش مدل کار سادهای بوده، اما در واقعیت اینطور نیست. قبل از دستیابی به دقت ۸۳% نسخههای زیاد دیگری از مدل بودند که عملکرد ضعیفی از خود نشان دادند؛ یا در یکی از دفعات اجرا (تکرارها) ورودیها را به درستی مقیاسبندی نکردیم و این باعث شد مدل به همهی فایلها برچسب «متعجب» اختصاص دهد. اما نکتهی مهم آن چیزی است که از این تجارب میآموزیم.
اولاً این پروژه به خوبی نشان داد جمعآوری داده تا چه حد میتواند نتایج را بهبود بخشد. اولین اجرای موفقیتآمیز مدل زمانی بود که مدل تنها از دیتاست RAVDESS (شامل حدود ۱۴۰۰ فایل صوتی) استفاده کرد؛ بهترین دقتی که مدل با استفاده از این دیتاست به دست آورد ۶۷% بود. برای رسیدن به دقت نهایی ۸۳% اندازهی دیتاست را افزایش داده و به ۴۵۰۰ فایل رساندیم.
دومین درسی که از این پروژه گرفتیم این بود که پیشپردازش دادههای ردهبندی صوتی ضروری است؛ زیرا صوت خام و حتی تبدیلات فوریه زمانکوتاه تقریباً به کل بلااستفاده هستند. نکته دیگیری که به سختی متوجه شدیم این بود که مقیاسبندی نقشی تعیینکننده برای مدل دارد. اگر نتوانیم سکوت را حذف کنیم نیز مشکل دیگری پیش میآید. بعد از تبدیل صوت به ویژگیهای آگاهیبخش، ساخت و آموزش مدل یادگیری عمیق تا حد زیادی تسهیل میشود.
در جمعبندی مطلب میتوانم بگویم ساخت یک مدل دستهبندی برای تشخیص عواطف صوتی تجربهای چالشبرانگیز اما آموزنده بود. در آیندهای نزدیک احتمالاً به این پروژه برخواهیم گشت و آن را گسترش میدهیم. از برخی عواملی که شاید به آن اضافه کنیم میتوانم به این موارد اشاره کرد: آزمایش مدل روی ورودیهای بیشتر، سازگار کردن مدل با عواطف بیشتر و پیادهسازی مدل برای تشخیص عاطفه در فضای ابری به صورت لحظهای.
منبع: هوشیو




سلام وقتتون بخیر
منبع هوشیو هست نه هوشینو لطفا درستش کنین
سلام و با سپاس از اطلاع رسانی
اصلاح شد